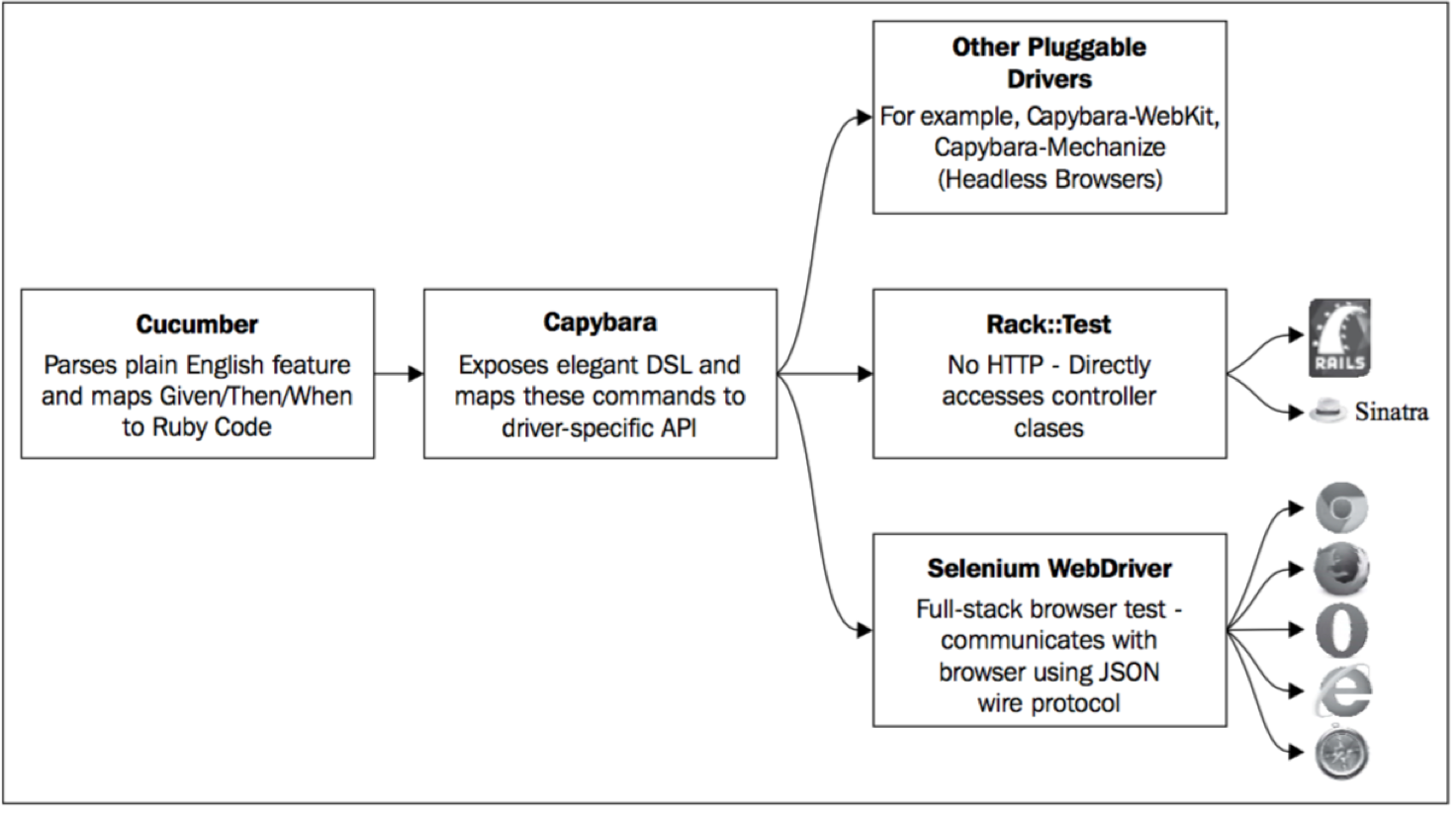
前言
前2篇我们已经详细介绍了espresso的架构以及相应的API,相信大家也有了一定的了解,理论讲的再多,还是不如手上自己敲一遍代码。
还是深入浅出系列的套路,让我这个小司机带大家一步一步进入espresso的世界吧。
环境准备

github,如果你还用svn的话,请放弃阅读本系列文章,太low了,而且本系列的code都是采用google官方的espresso的demo,都来源于github。
android studio,这个不用说,目前android开发者最好的工具,并且他有很多帮助espresso测试的插件或功能,比如录制功能等。![]()
android sdk,这个更不用说,如果你连这个都没,还学什么android。
genymotion,android目前来说最好的模拟器,虽然原生的也很不错,但是开发者首先得还是genymotion
首先使用android studio创建项目
最好你已经拥有了项目源码,espresso并不是单纯的黑盒ui测试工具,它能干得事情很多,包括单元测试,集成测试,甚至在mock服务,以及将你需要的内容注入到代码中,所以我把称为灰盒工具。
如果之前没有做个android项目的话,也可以在github上找一些开源的android app 练手。不过建议大家从espresso demo库入手。
创建项目

如上图,我们可以创建新的项目,导入已经存在android项目,从版本管理软件中导入,从gradle等其他工具中导入,以及获取android代码样例导入。
google android 所有的测试demo都在以下github地址
https://github.com/googlesamples/android-testing.git
下载完成后,我们进入espresso目录,可以看到espresso的demo还是很丰富的。
导入项目
选择BasicSample导入或者直接命令行studio .打开该项目。 ·
·
外层的build.gradle文件设置的是整个项目的一些配置,例如依赖的类库,远程的仓库repositories。编译器的版本,espresso的版本等。
|
|
目录结构
app目录为项目主目录包含项目源代码以及测试代码
app里面也包含build.gradle文件,有时候项目可能包含几个主目录,那么各个目录的下的build.gradle文件都继承自顶层的build.gradle文件。
app下的build.gradle文件配置了android的配置信息,以及会用到的依赖。
|
|
BasicSample APP就长样子。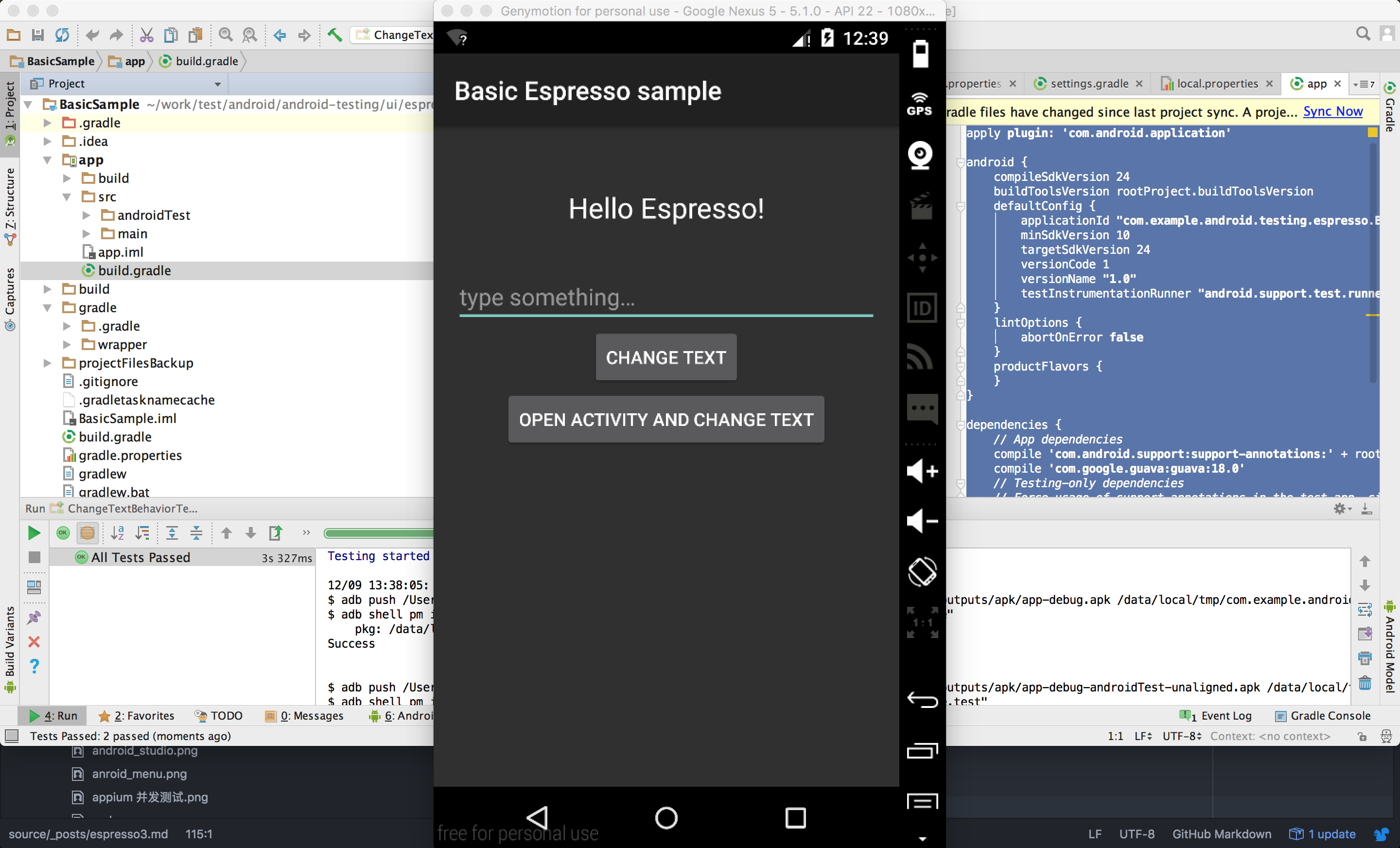
启动模拟器
首先启动android emulator/genymotion,之后直接点击run按钮就能部署app到模拟器上。
log如下.
编写测试
此实例BasicSample包含1个textView,1个EditText和2个button,当点击change text 按钮时,会将edittext的值填入textview中。当点击open activity and change text 按钮时,将打开一个新的页面(姑且叫这样吧)并将edittext内容显示在这个页面。@RunWith(AndroidJUnit4.class)
采用了JUnit 4风格进行编写
- 首先我们需要新建一个测试类。
ChangeTextBehaviorTest
|
|
- 首先创建一个@Rule,ActivityTestRule用来指明被测试的Activity;
@Rule: 简单来说,是为各个测试方法提供一些支持。具体来说,比如我需要测试一个Activity,那么我可以在@Rule注解下面采用一个ActivityTestRule,该类提供了对相应Activity的功能测试的支持。该类可以在@Before和@Test标识的方法执行之前确保将Activity运行起来,并且在所有@Test和@After方法执行结束之后将Activity杀死。在整个测试期间,每个测试方法都可以直接对相应Activity进行修改和访问。
|
|
- 标识一个测试方法。一个测试类中可以有多个测试方法,每个测试方法需要用一个@Test注解来标识。
以下代码找到editTextUserInput输入‘Espresso’,关闭键盘。点击changeTextBt按钮。检查textToBeChanged的值是否为‘Espresso’。12345678910@Testpublic void changeText_sameActivity() {// Type text and then press the button.onView(withId(R.id.editTextUserInput)).perform(typeText(STRING_TO_BE_TYPED), closeSoftKeyboard());onView(withId(R.id.changeTextBt)).perform(click());// Check that the text was changed.onView(withId(R.id.textToBeChanged)).check(matches(withText(STRING_TO_BE_TYPED)));}
顺便说说其他junit4注解的用法
@Before: 标识在运行测试方法之前运行的代码。可以支持同一个Class中有多个@Before,但是这些方法的执行顺序是随机的。该注解替代了JUnit 3中的setUp()方法。
@After: 标识在运行测试方法结束之后运行的代码。可以在其中做一些释放资源的操作。该注解替代了JUnit 3中的tearDown()方法。
@BeforeClass: 为测试类标识一个static方法,在测试之前只执行一次。
@AfterClass: 为测试类标识一个static方法,在所有测试方法结束之后只执行一次。
@Test(timeout=<milliseconds>): 为测试方法设定超时时间。
到了这里我们要说下怎么定位所需的元素,其实和web差不多,我们可以利用layout inspector与android device monitor工具。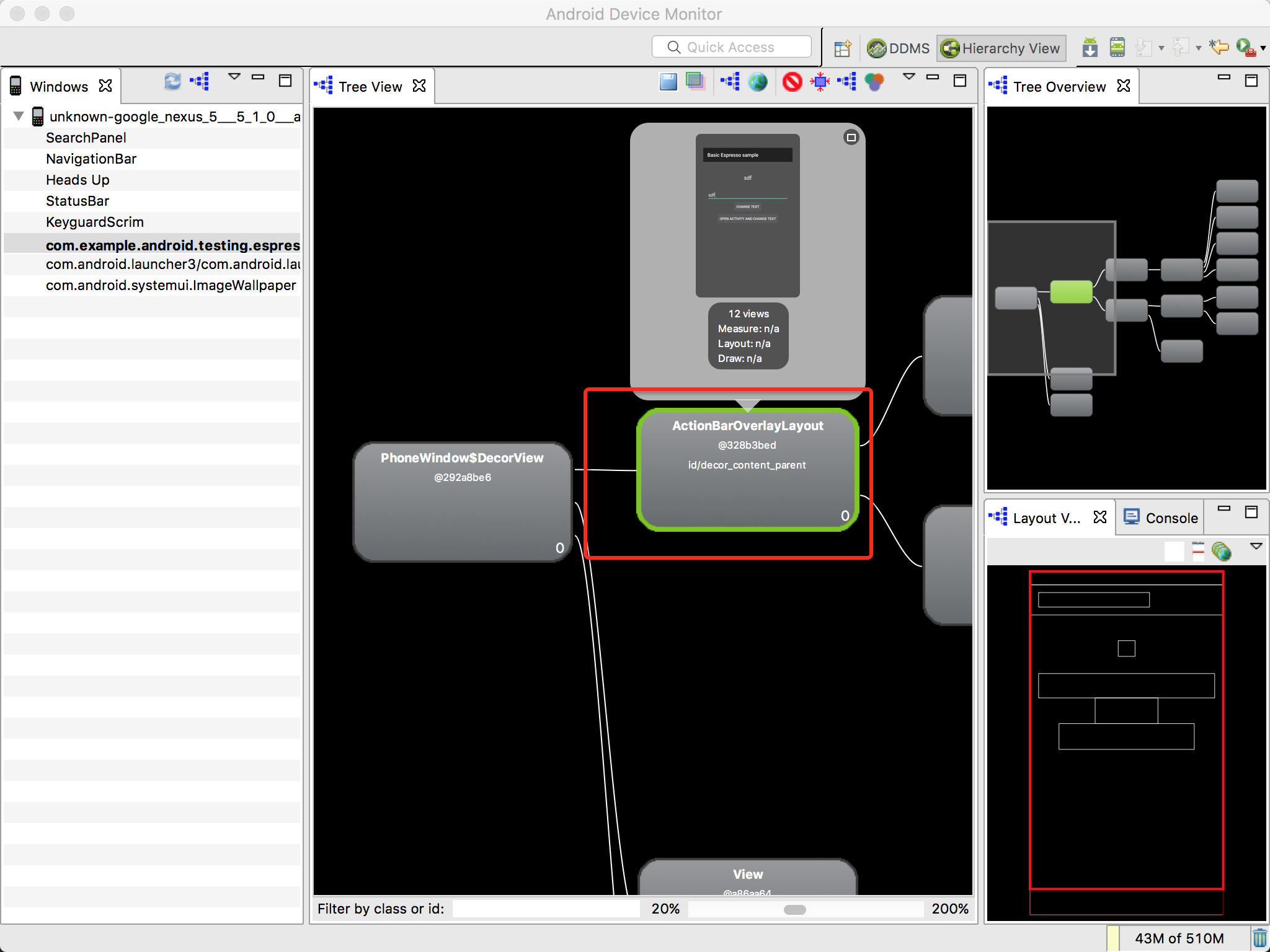
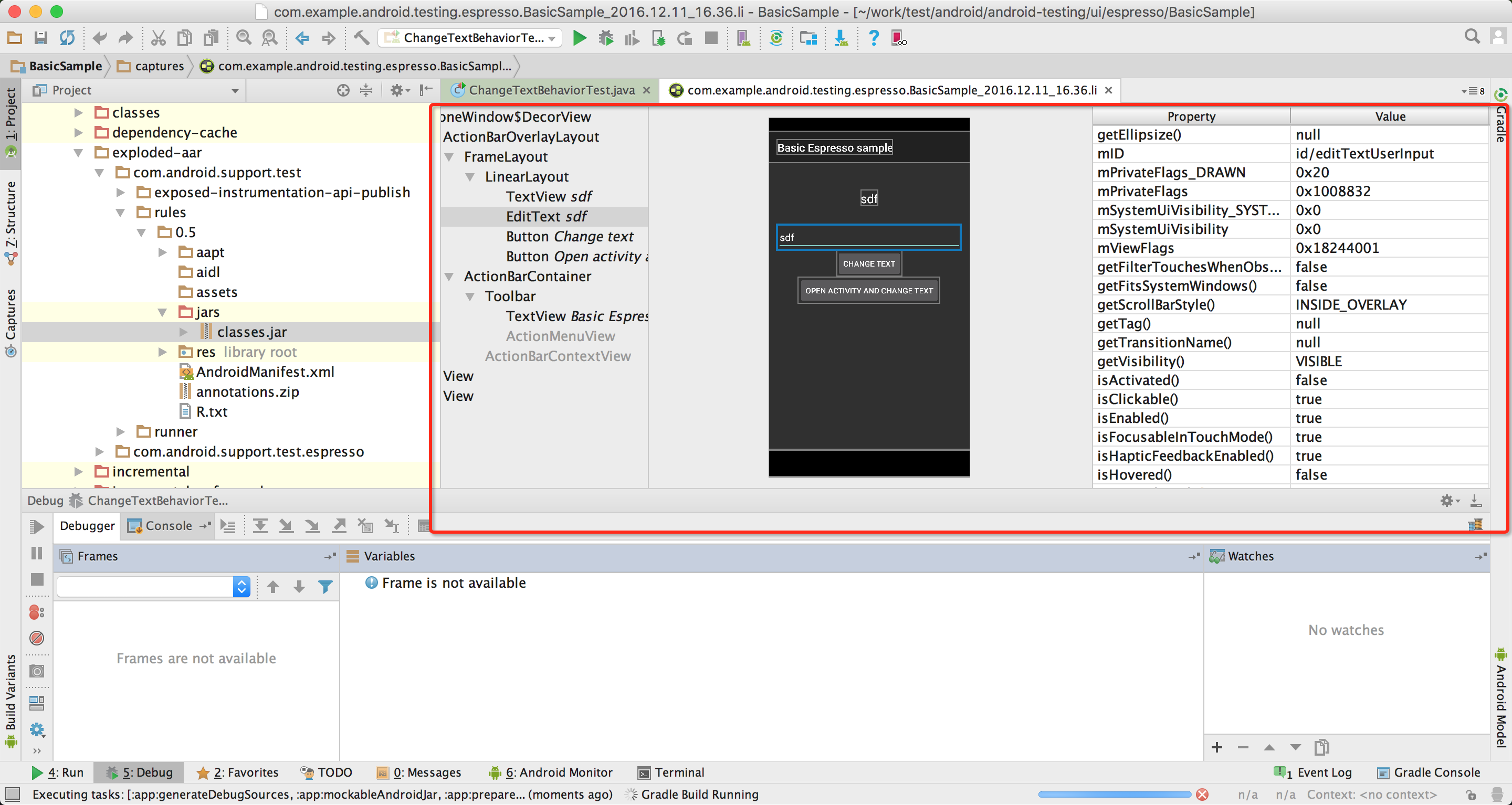
在写一个测试,在editTextUserInput输入‘Espresso’,之后关闭键盘。点击activityChangeTextBtn按钮,查看show_text_view的值是否为‘Espresso’。
以上是espresso最常见的测试,希望大家能够好好理解。
接下来我们看看espresso如何对AdapterView控制器测试。
AdapterView 是一个从适配器中动态加载数据的特殊控件。最常见的 AdapterView 是 ListView。与像 LinearLayout 这样的静态控件相反,在当前视图结构中,可能只加载了 AdapterView 子控件的一部分, 简单的 onview() 可能会找不到当前没有被加载的视图。Espresso 通过提供单独的 onData()方法来切入点处理此问题,它可以在操作适配器中有该问题的条目或该条目的子项之前将其加载(使其获取焦点)。
导入espresso demo中的MultiWindowSample项目
该测试是从ArrayAdapter类型的dropdown_item控件中选出需要的值,类似我们用搜索引擎时,显示的list。
,AutoCompleteText的选择等。 这些测试项都有一个共同的特点。即不在主UI布局的结构(layout,及其include的layout)之中,是不能直接定位的。 所以这里就需要使用inRoot( ) 了。onData(allOf(instanceOf(String.class), is("Baltic Sea")))
.inRoot(withDecorView(not(is(mActivity.getWindow().getDecorView()))))
.perform(click());
以上代码就解决了之前UiAutomator不支持Toast的验证的问题。
运行测试
运行测试的方法很多,第一种命令行执行。
切换到当前项目目录,终端运行./gradlew cAT
其中,cAT意为connectedAndroidTest。
另一种方式是在android studio中,点击run按钮,或者右键执行单一测试。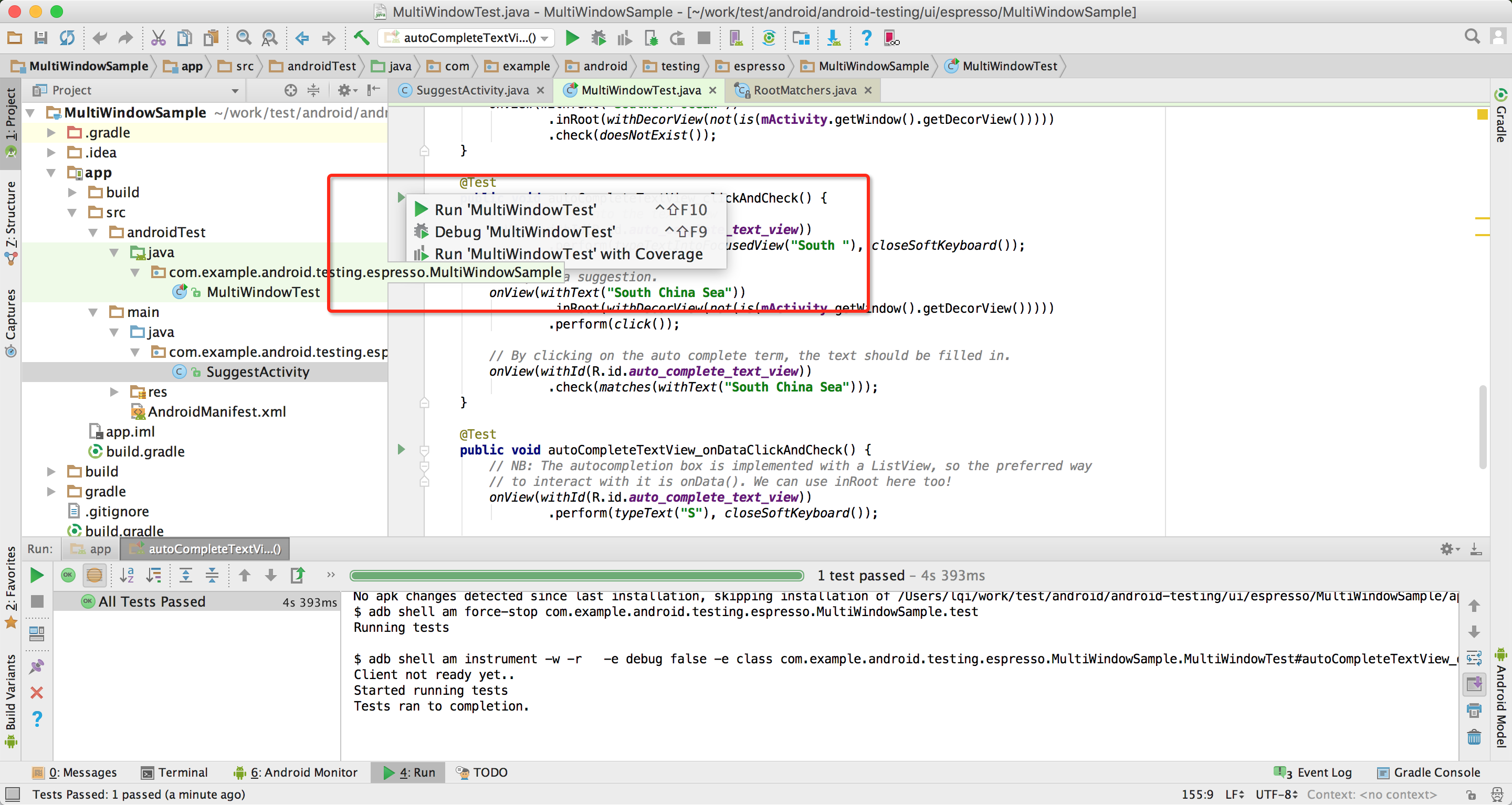
这一章还是以基础的实践为主,之后我们将深入架构,来看看espresso的API 方法,帮助大家理解API 更好更快的编写测试。